目錄
- 一��、什么是停用詞
- 二��、加載停用詞字典
- 三���、刪除停用詞
- 四、分詞以及刪除停用詞
- 五�、直接刪除停用詞(不分詞)
一、什么是停用詞
在漢語中�,有一類沒有多少意義的詞語,比如組詞“的”����,連詞“以及”、副詞“甚至”��,語氣詞“吧”���,被稱為停用詞����。一個句子去掉這些停用詞����,并不影響理解���。所以,進行自然語言處理時�����,我們一般將停用詞過濾掉�。
而HanLP庫提供了一個小巧的停用詞字典,它位于Lib\site-packages\pyhanlp\static\data\dictionary目錄中�,名字為:stopwords.txt。該文本收錄了常見的中英文無意義的詞匯�����,每行一個詞語��。示例如下:

我們在進行自然語言處理時�����,可以用BinTrie����、DoubleArrayTrie和AhoCorasickDoubleArrayTrie中的任意一個來存儲詞典�����。考慮到該詞典中都是短語且比較多����,用雙數(shù)組字典樹更劃算,處理時間更快�����。
二�����、加載停用詞字典
通過前文的介紹���,我們知道了使用雙數(shù)組字典樹加載停用詞字典更劃算��。下面���,我們來加載其停用詞,并返回鍵值對結構����。代碼如下:
def load_dictionary(path):
map=JClass('java.util.TreeMap')()
with open(path,encoding='utf-8') as src:
for word in src:
word=word.strip()
map[word]=word
return JClass('com.hankcs.hanlp.collection.trie.DoubleArrayTrie')(map)
三��、刪除停用詞
通過上面的停用詞加載�,我們獲取了DoubleArrayTrie樹結構的詞匯�����。如果要刪除停用詞�����,可以直接使用分詞后的結果剔除停用詞即可�����。剔除的方法如下:
def remove_stopwords(termlist,trie):
return [term.word for term in termlist if not trie.containsKey(term.word)]
四����、分詞以及刪除停用詞
在前面的博文中,我們已經(jīng)學會了如何分詞���,現(xiàn)在我們又學會了如何剔除停用詞��。這里�����,我們將兩者結合起來�����,實現(xiàn)分詞效果��。代碼如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=False
trie=load_dictionary(HanLP.Config.CoreStopWordDictionaryPath)
text="今天就這樣吧��!明天我們在說可以嗎���?"
segment=DoubleArrayTrieSegment()
termlist=segment.seg(text)
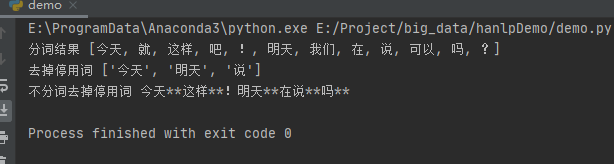
print("分詞結果",termlist)
print("去掉停用詞",remove_stopwords(termlist,trie))
運行之后,得到如下結果:

五�����、直接刪除停用詞(不分詞)
對應上面的結果�����,我們先分詞在刪除停用詞���。但是�,有時候我們也喜歡先刪除停用詞在進行分詞。下面����,我們來實現(xiàn)直接刪除停用詞。
代碼如下:
#直接過濾方法
def direct_remove_stopwords(text,replacement,trie):
JString=JClass('java.lang.String')
searcher=trie.getLongestSearcher(JString(text),0)
offset=0
result=''
while searcher.next():
begin=searcher.begin
end=begin+searcher.length
if begin>offset:
result+=text[offset:begin]
result+=replacement
offset=end
if offsetlen(text):
result+=text[offset:]
return result
if __name__ == "__main__":
HanLP.Config.ShowTermNature = False
trie = load_dictionary(HanLP.Config.CoreStopWordDictionaryPath)
text = "今天就這樣吧���!明天我們在說可以嗎�����?"
segment = DoubleArrayTrieSegment()
termlist = segment.seg(text)
print("分詞結果", termlist)
print("去掉停用詞", remove_stopwords(termlist, trie))
print("不分詞去掉停用詞", direct_remove_stopwords(text, "**", trie))
運行之后��,效果如下:
到此這篇關于python基礎之停用詞過濾詳解的文章就介紹到這了,更多相關python停用詞過濾內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- python使用jieba實現(xiàn)中文分詞去停用詞方法示例
- 利用Python過濾相似文本的簡單方法示例
- Python實現(xiàn)敏感詞過濾的4種方法
- Python過濾序列元素的方法
- python numpy實現(xiàn)多次循環(huán)讀取文件 等間隔過濾數(shù)據(jù)示例
- python正則過濾字母���、中文、數(shù)字及特殊字符方法詳解
