目錄
- 一、使用PyChram的正則
- 二�、制作一個隨機User-Agent模塊
- 三、最終實踐
- 3.1 爬取快代理上的ip
- 3.2 驗證爬取到的ip是否可用
- 3.3 實戰(zhàn):利用爬取到的ip訪問CSDN博客網(wǎng)址1000次
- 四�����、總結(jié)
一�����、使用PyChram的正則
首先��,小編講的不是爬取ip�����,而是講了解PyCharm的正則���,這里講的正則不是Python的re模塊哈��!
而是PyCharm的正則功能���,我們在PyChram的界面上按上Ctrl+R,可以發(fā)現(xiàn)�����,這里出現(xiàn)兩行輸入框

現(xiàn)在如果小編想把如下數(shù)據(jù)轉(zhuǎn)換成一個字典存儲
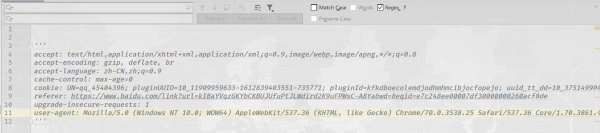
讀者也許會一個一去改,但是小編只需在上述的那兩個輸入框內(nèi)���,輸入一串字符串即可。

只需在第一個輸入框中����,輸入(.*) : (.*)
在第二個輸入框中,輸入"$1":"$2",,看看效果如何

之后再給兩端分別一個花括號和取一個字典名稱即可�。
二、制作一個隨機User-Agent模塊
反爬措施中�,有這樣一條,就是服務(wù)器會檢查請求的user-agent參數(shù)值���,如果檢查的結(jié)果為python�,那么服務(wù)器就知道這是爬蟲����,為了避免被服務(wù)器發(fā)現(xiàn)這是爬蟲,通常user-agent參數(shù)值會設(shè)置瀏覽器的值���,但是爬取一個網(wǎng)址時�,每次都需要查看網(wǎng)址network下面的內(nèi)容,顯得比較繁瑣���,為什么不自定義一個隨機獲取user-agent的值模塊呢����?這樣既可以減少查看network帶來的繁瑣���,同時還可以避免服務(wù)器發(fā)現(xiàn)這是同一個user-agent發(fā)起多次請求�����。
說了這么多�,那么具體怎樣實現(xiàn)呢��?

只需調(diào)用隨機模塊random的方法choice()即可��,這個方法里面的參數(shù)類型時列表類型���,具體參考代碼如下:
import random
class useragent(object):
def getUserAgent(self):
useragents=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
]
return random.choice(useragents)
這樣我們就可以隨機得到一個user-agent的值了�。
三���、最終實踐
3.1 爬取快代理上的ip
接下來�����,就是最終實踐了���,制作屬于自己的IP代理模塊����。
那么�,從哪里獲取IP呢�����?小編用的是快代理這個網(wǎng)址����,網(wǎng)址鏈接為:https://www.kuaidaili.com/free/inha/1/。
怎樣提取IP呢��?小編用的是xpath語法

參考代碼如下:
import requests
from crawlers.userAgent import useragent # 導(dǎo)入自己自定義的類�����,主要作用為隨機取user-agent的值
from lxml import etree
url='https://www.kuaidaili.com/free/inha/1/'
headers={'user-agent':useragent().getUserAgent()}
rsp=requests.get(url=url,headers=headers)
HTML=etree.HTML(rsp.text)
infos=HTML.xpath("http://table[@class='table table-bordered table-striped']/tbody/tr")
for info in infos:
print(info.xpath('./td[1]/text()')) # ip
print(info.xpath('./td[2]/text()')) # ip對應(yīng)的端口 列表類型
怎樣爬取多頁呢?分析快代理那個網(wǎng)址��,可以發(fā)現(xiàn)https://www.kuaidaili.com/free/inha/{頁數(shù)}/ ���,花括號里面就是頁數(shù)���,這個網(wǎng)址總頁數(shù)為4038,這里小編只爬取5頁��,并且開始頁數(shù)?��。?��,3000)之間的隨機數(shù)�,但是如果for循環(huán)這個過程���,運行結(jié)果如下:
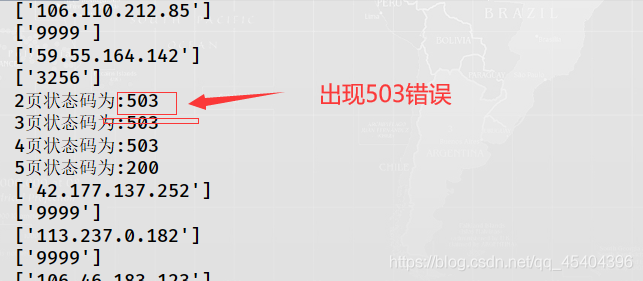
原來是請求過快的原因����,只需在爬取1頁之后����,休眠幾秒鐘即可解決。
3.2 驗證爬取到的ip是否可用
這里直接用百度這個網(wǎng)址作為測試網(wǎng)址,主要代碼為:
url='https://www.baidu.com'
headers={'user-agent':useragent().getUserAgent()}
proxies={} # ip ��,這里只是講一下關(guān)鍵代碼��,沒有給出具體IP
rsp=requests.get(url=url,headers=headers,proxies=proxies,time=0.2) # timeout為超時時間
只需判斷rsp的狀態(tài)碼為200�,如果是,把它添加到一個指定的列表中�。
具體參考代碼小編已經(jīng)上傳到Gitee上,鏈接為:ip代理模塊
當然讀者可用把這個文件保存到python\Lib文件夾下面���,這樣就可用隨時隨地導(dǎo)入了���。
3.3 實戰(zhàn):利用爬取到的ip訪問CSDN博客網(wǎng)址1000次
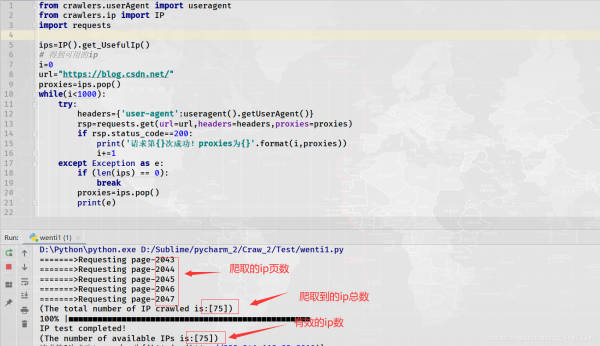


上述出現(xiàn)那個錯誤,小編上網(wǎng)搜索了一下原因��,如下:

我想應(yīng)該是第1種原因�����,ip被封����,我這里沒有設(shè)置超時時間�,應(yīng)該不會出現(xiàn)程序請求速度過快。
四、總結(jié)
上述那個ip代理模塊還有很多的不足點����,比如用它去訪問一些網(wǎng)址時,不管運行多少次�����,輸出的結(jié)果狀態(tài)碼不會時200�����,這也正常����,畢竟免費的ip并不是每個都能用的。如果要說改進的話����,就是多爬取幾個不同ip代理網(wǎng)址,去重���,這樣的結(jié)果肯定會比上述的那個ip代理模塊要好
到此這篇關(guān)于python爬蟲實戰(zhàn)之制作屬于自己的一個IP代理模塊的文章就介紹到這了,更多相關(guān)Python IP代理模塊內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家���!
您可能感興趣的文章:- python利用proxybroker構(gòu)建爬蟲免費IP代理池的實現(xiàn)
- Python爬蟲設(shè)置ip代理過程解析
- python如何基于redis實現(xiàn)ip代理池
- python3 Scrapy爬蟲框架ip代理配置的方法
- Python爬蟲動態(tài)ip代理防止被封的方法
- python實現(xiàn)ip代理池功能示例
- python單例模式獲取IP代理的方法詳解
- python3 requests中使用ip代理池隨機生成ip的實例
