我們學習編程����,在學習的時候,會有想把有用的知識點保存下來���,我們可以把知識點的內(nèi)容爬下來轉(zhuǎn)變成pdf格式��,方便我們拿手機可以閑時翻看�,是很方便的
先來一個單個的博文下載轉(zhuǎn)pdf格式的操作

python中將html轉(zhuǎn)化為pdf的常用工具是Wkhtmltopdf工具包���,在python環(huán)境下�,pdfkit是這個工具包的封裝類�。如何使用pdfkit以及如何配置呢?分如下幾個步驟��。
下載wkhtmltopdf安裝包��,并且安裝到電腦上���。
下載地址:https://wkhtmltopdf.org/downloads.html
我下的是這個版本�,安裝的時候要記住路徑����,之后調(diào)用要用到路徑

開發(fā)工具
- python
- pycharm
- pdfkit (pip install pdfkit)
- lxml
今天目標:博主的全部博文下載,并且轉(zhuǎn)pdf格式保存
基本思路:
1���、url + headers
2����、分析網(wǎng)頁: CSDN網(wǎng)頁是靜態(tài)網(wǎng)頁, 請求獲取網(wǎng)頁源代碼
3��、lxml解析獲取boke_urls, author_name
4�、循環(huán)遍歷,得到 boke_url
5���、xpath解析獲取文件名
6����、css選擇器獲取標簽文本的主體
7�、構(gòu)造拼接html文件
8、保存html文件
9����、文件的轉(zhuǎn)換
分析網(wǎng)頁: CSDN網(wǎng)頁是靜態(tài)網(wǎng)頁, 請求獲取網(wǎng)頁源代碼
start_url =“https://i1bit.blog.csdn.net/” 為例
確定網(wǎng)址為同步加載
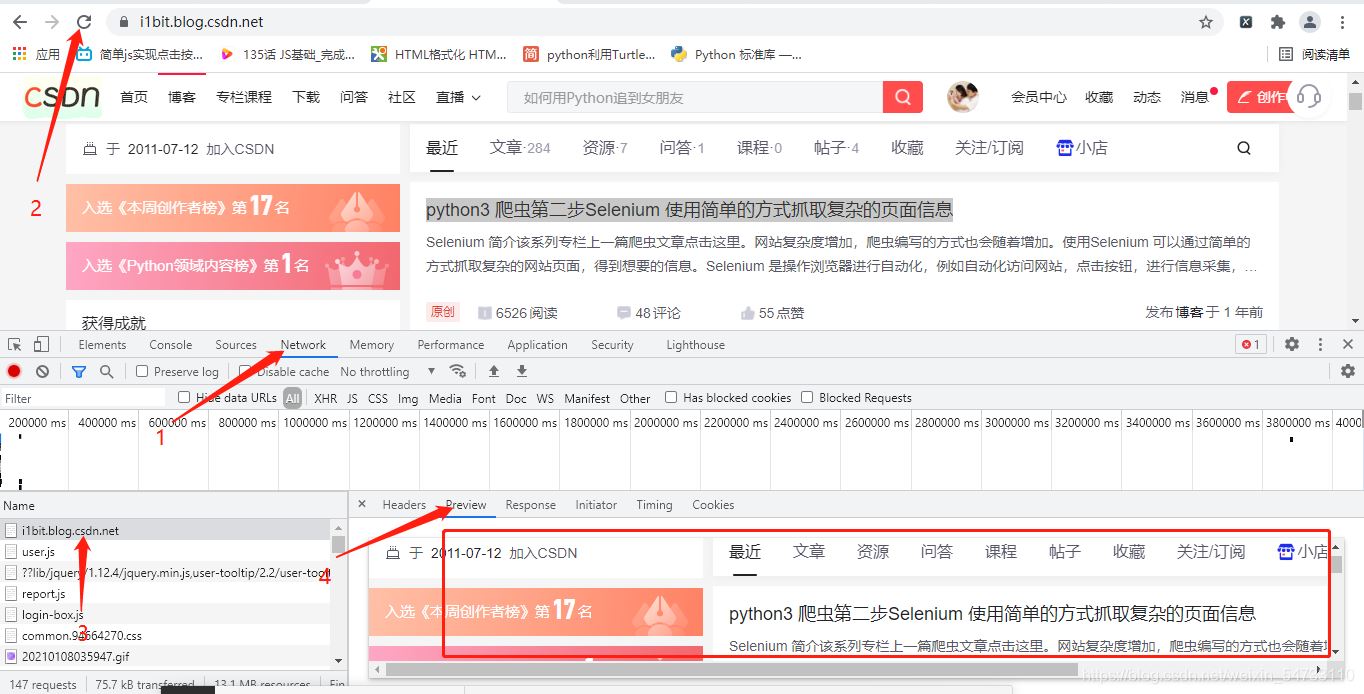
css選擇器獲取標簽文本的主體為代碼要點部分
css語法部分
# css選擇器獲取標簽文本的主體
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 構(gòu)造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
點開博主的一篇博文打開開發(fā)者工具
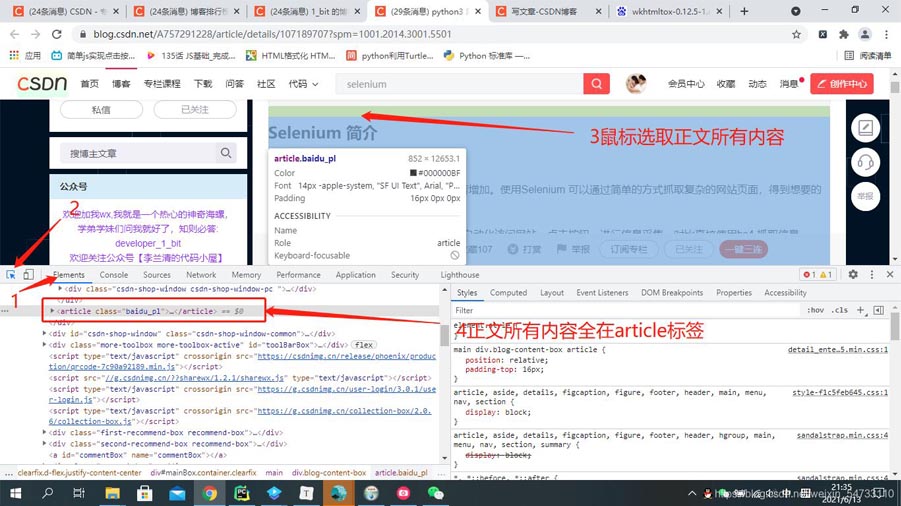
# css選擇器獲取標簽文本的主體
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 構(gòu)造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
文件的轉(zhuǎn)換
config = pdfkit.configuration(wkhtmltopdf=r'這里為下載wkhtmltopdf.exe的路徑')
pdfkit.from_file(
第一個參數(shù)要轉(zhuǎn)變的html文件,
第二個參數(shù)轉(zhuǎn)變后的pdf文件,
configuration=config
)
# 上面這樣寫清楚一點�����,也可以直接
pdfkit.from_file(
第一個參數(shù)要轉(zhuǎn)變的html文件,
第二個參數(shù)轉(zhuǎn)變后的pdf文件,
configuration=pdfkit.configuration(wkhtmltopdf=r'這里為下載wkhtmltopdf.exe的路徑')
)
源碼展示:
import parsel, os, pdfkit
from lxml import etree
from requests_html import HTMLSession
session = HTMLSession()
def main():
# 1�、url + headers
start_url = input(r'請輸入csdn博主的地址:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 2、分析網(wǎng)頁: CSDN網(wǎng)頁是靜態(tài)網(wǎng)頁, 請求獲取網(wǎng)頁源代碼
response_1 = session.get(start_url, headers=headers).text
# 3���、解析獲取boke_urls, author_name
html_xpath_1 = etree.HTML(response_1)
author_name = html_xpath_1.xpath(r'//*[@id="floor-user-profile_485"]/div/div[1]/div[2]/div[2]/div[1]/div[1]/text()')[0]
boke_urls = html_xpath_1.xpath(r'//article[@class="blog-list-box"]/a/@href')
# 4�、循環(huán)遍歷��,得到 boke_url
for boke_url in boke_urls:
# 5���、請求
response_2 = session.get(boke_url, headers=headers).text
# 6����、xpath解析獲取文件名
html_xpath_2 = etree.HTML(response_2)
file_name = html_xpath_2.xpath(r'//h1[@id="articleContentId"]/text()')[0]
# 7���、css選擇器獲取標簽文本的主體
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 8、構(gòu)造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
# 9�、創(chuàng)建兩個文件夾, 一個用來保存html 一個用來保存pdf文件
if not os.path.exists(r'{}-html'.format(author_name)):
os.mkdir(r'{}-html'.format(author_name))
if not os.path.exists(r'{}-pdf'.format(author_name)):
os.mkdir(r'{}-pdf'.format(author_name))
# 10����、保存html文件
try:
with open(r'{}-html/{}.html'.format(author_name, file_name), 'w', encoding='utf-8') as f:
f.write(html)
except Exception as e:
print('文件名錯誤')
# 11、文件的轉(zhuǎn)換
try:
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(
'{}-html/{}.html'.format(author_name, file_name),
'{}-pdf/{}.pdf'.format(author_name, file_name),
configuration=config
)
a = print(r'--文件下載成功:{}.pdf'.format(file_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
代碼操作:

到此這篇關(guān)于python實現(xiàn)csdn全部博文下載并轉(zhuǎn)PDF的文章就介紹到這了,更多相關(guān)python 博文下載并轉(zhuǎn)PDF內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家�����!
您可能感興趣的文章:- python解析PDF程序代碼
- Python合并多張圖片成PDF
- Python提取PDF指定內(nèi)容并生成新文件
- 詳解用Python把PDF轉(zhuǎn)為Word方法總結(jié)
- python操作mysql�、excel��、pdf的示例
- python pdfkit 中文亂碼問題的解決方案
- python 三種方法提取pdf中的圖片
- Python實現(xiàn)給PDF添加水印的方法
- Python讀取pdf表格寫入excel的方法
- Python 多張圖片合并成一個pdf的參考示例
